Selected Publications
|

|
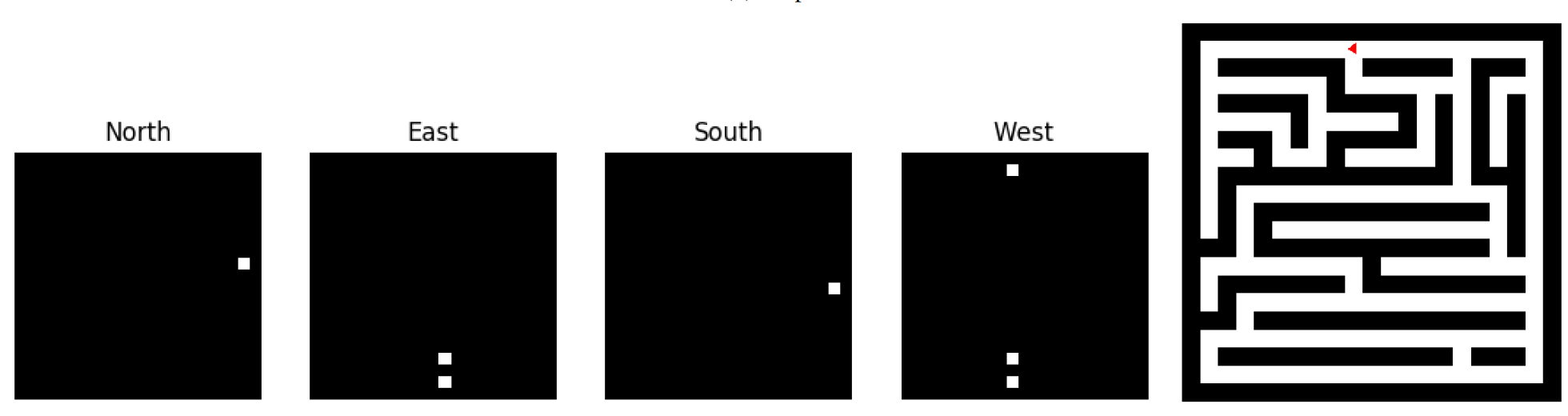
RoboPoint: A Vision-Language Model for Spatial Affordance Prediction for Robotics
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, Dieter Fox
arXiv preprint arXiv:2406.10721, 2024
paper /
abstract /
project page /
bibtex
From rearranging objects on a table to putting groceries into shelves, robots must plan precise action points to perform tasks accurately and reliably. In spite of the recent adoption of vision language models (VLMs) to control robot behavior, VLMs struggle to precisely articulate robot actions using language. We introduce an automatic synthetic data generation pipeline that instruction-tunes VLMs to robotic domains and needs. Using the pipeline, we train RoboPoint, a VLM that predicts image keypoint affordances given language instructions. Compared to alternative approaches, our method requires no real-world data collection or human demonstration, making it much more scalable to diverse environments and viewpoints. In addition, RoboPoint is a general model that enables several downstream applications such as robot navigation, manipulation, and augmented reality (AR) assistance. Our experiments demonstrate that RoboPoint outperforms state-of-the-art VLMs (GPT-4o) and visual prompting techniques (PIVOT) by 21.8% in the accuracy of predicting spatial affordance and by 30.5% in the success rate of downstream tasks.
@article{yuan2024robopoint,
title={RoboPoint: A Vision-Language Model for Spatial Affordance Prediction for Robotics},
author={Yuan, Wentao and Duan, Jiafei and Blukis, Valts and Pumacay, Wilbert and Krishna, Ranjay and Murali, Adithyavairavan and Mousavian, Arsalan and Fox, Dieter},
journal={arXiv preprint arXiv:2406.10721},
year={2024}
}
|
|
|
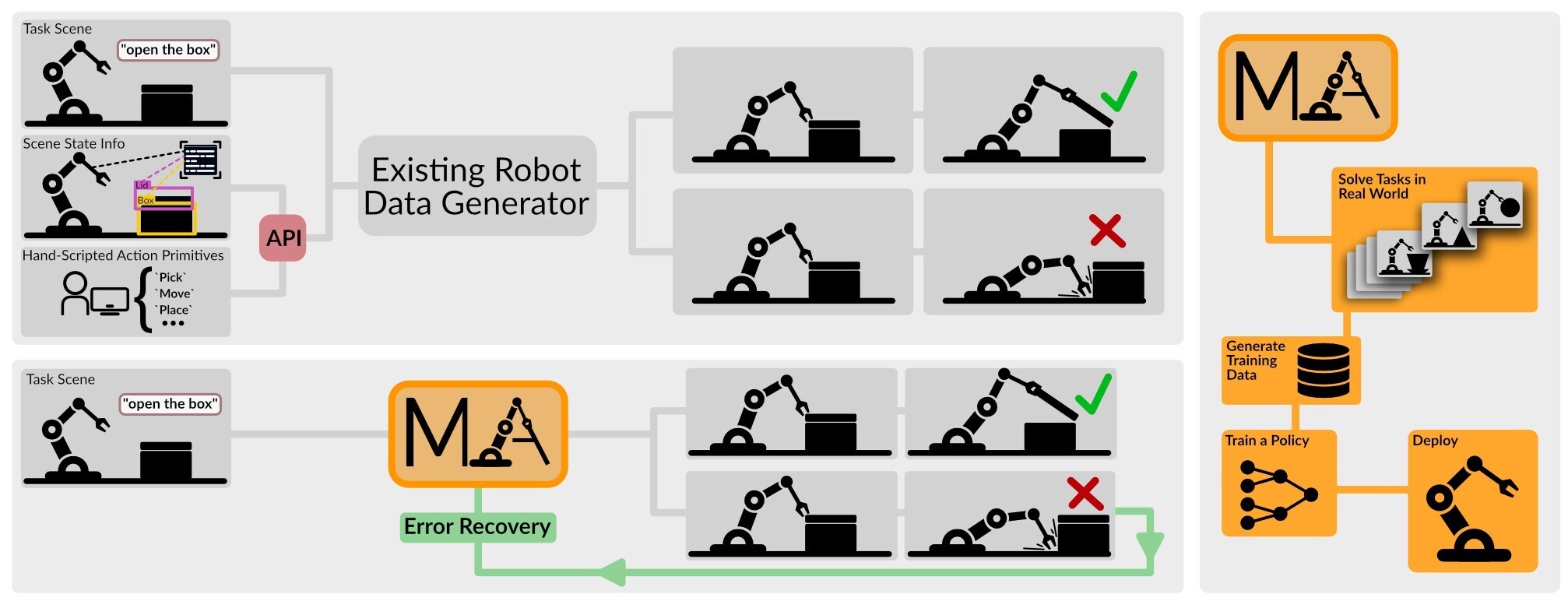
Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
Jiafei Duan, Wentao Yuan, Wilbert Pumacay, Yi Ru Wang, Kiana Ehsani, Dieter Fox, Ranjay Krishna
arXiv preprint arXiv:2406.18915, 2024
paper /
abstract /
project page /
bibtex
Large-scale endeavors like RT-1 and widespread community efforts such as Open-X-Embodiment have contributed to growing the scale of robot demonstration data. However, there is still an opportunity to improve the quality, quantity, and diversity of robot demonstration data. Although vision-language models have been shown to automatically generate demonstration data, their utility has been limited to environments with privileged state information, they require hand-designed skills, and are limited to interactions with few object instances. We propose Manipulate-Anything, a scalable automated generation method for real-world robotic manipulation. Unlike prior work, our method can operate in real-world environments without any privileged state information, hand-designed skills, and can manipulate any static object. We evaluate our method using two setups. First, Manipulate-Anything successfully generates trajectories for all 5 real-world and 12 simulation tasks, significantly outperforming existing methods like VoxPoser. Second, Manipulate-Anything's demonstrations can train more robust behavior cloning policies than training with human demonstrations, or from data generated by VoxPoser and Code-As-Policies. We believe Manipulate-Anything can be the scalable method for both generating data for robotics and solving novel tasks in a zero-shot setting.
@article{duan2024manipulate,
title={Manipulate-Anything: Automating Real-World Robots using Vision-Language Models},
author={Duan, Jiafei and Yuan, Wentao and Pumacay, Wilbert and Wang, Yi Ru and Ehsani, Kiana and Fox, Dieter and Krishna, Ranjay},
journal={arXiv preprint arXiv:2406.18915},
year={2024}
}
|
|

|
M2T2: Multi-Task Masked Transformer for Object-centric Pick and Place
Wentao Yuan, Adithyavairavan Murali, Arsalan Mousavian, Dieter Fox
The Conference on Robot Learning (CoRL), 2023
paper /
abstract /
code /
project page /
bibtex
With the advent of large language models and large-scale robotic datasets, there has been tremendous progress in high-level decision-making for object manipulation. These generic models are able to interpret complex tasks using language commands, but they often have difficulties generalizing to out-of-distribution objects due to the inability of low-level action primitives. In contrast, existing task-specific models excel in low-level manipulation of unknown objects, but only work for a single type of action. To bridge this gap, we present M2T2, a single model that supplies different types of low-level actions that work robustly on arbitrary objects in cluttered scenes. M2T2 is a transformer model which reasons about contact points and predicts valid gripper poses for different action modes given a raw point cloud of the scene. Trained on a large-scale synthetic dataset with 128K scenes, M2T2 achieves zero-shot sim2real transfer on the real robot, outperforming the baseline system with state-of-the-art task-specific models by about 19% in overall performance and 37.5% in challenging scenes where the object needs to be re-oriented for collision-free placement. M2T2 also achieves state-of-the-art results on a subset of language conditioned tasks in RLBench.
@inproceedings{yuan2023m2t2,
title={M2T2: Multi-Task Masked Transformer for Object-centric Pick and Place},
author={Yuan, Wentao and Murali, Adithyavairavan and Mousavian, Arsalan and Fox, Dieter},
booktitle={7th Annual Conference on Robot Learning},
year={2023}
}
|
|

|
SORNet: Spatial Object-Centric Representations for Sequential Manipulation
Wentao Yuan, Chris Paxton, Karthik Desingh, Dieter Fox
The Conference on Robot Learning (CoRL), 2021 (Oral)
[Best Systems Paper Finalist]
paper /
abstract /
code /
project page /
bibtex
Sequential manipulation tasks require a robot to perceive the state of an environment and plan a sequence of actions leading to a desired goal state, where the ability to reason about spatial relationships among object entities from raw sensor inputs is crucial. Prior works relying on explicit state estimation or end-to-end learning struggle with novel objects.
@inproceedings{yuan2021sornet,
title={SORNet: Spatial Object-Centric Representations for Sequential Manipulation},
author={Wentao Yuan and Chris Paxton and Karthik Desingh and Dieter Fox},
booktitle={5th Annual Conference on Robot Learning},
year={2021},
url={https://openreview.net/forum?id=mOLu2rODIJF}
}
|
|

|
STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering
Wentao Yuan, Zhaoyang Lv, Tanner Schmidt, Steven Lovegrove
The Conference on Computer Vision and Pattern Recognition (CVPR), 2021
paper /
abstract /
project page /
bibtex
We present STaR, a novel method that performs Self-supervised Tracking and Reconstruction of dynamic scenes with rigid motion from multi-view RGB videos without any manual annotation. Recent work has shown that neural networks are surprisingly effective at the task of compressing many views of a scene into a learned function which maps from a viewing ray to an observed radiance value via volume rendering. Unfortunately, these methods lose all their predictive power once any object in the scene has moved. In this work, we explicitly model rigid motion of objects in the context of neural representations of radiance fields. We show that without any additional human specified supervision, we can reconstruct a dynamic scene with a single rigid object in motion by simultaneously decomposing it into its two constituent parts and encoding each with its own neural representation. We achieve this by jointly optimizing the parameters of two neural radiance fields and a set of rigid poses which align the two fields at each frame. On both synthetic and real world datasets, we demonstrate that our method can render photorealistic novel views, where novelty is measured on both spatial and temporal axes. Our factored representation furthermore enables animation of unseen object motion.
@inproceedings{yuan2021star,
title={STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering},
author={Yuan, Wentao and Lv, Zhaoyang and Schmidt, Tanner and Lovegrove, Steven},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={13144--13152},
year={2021}
}
|
|
|
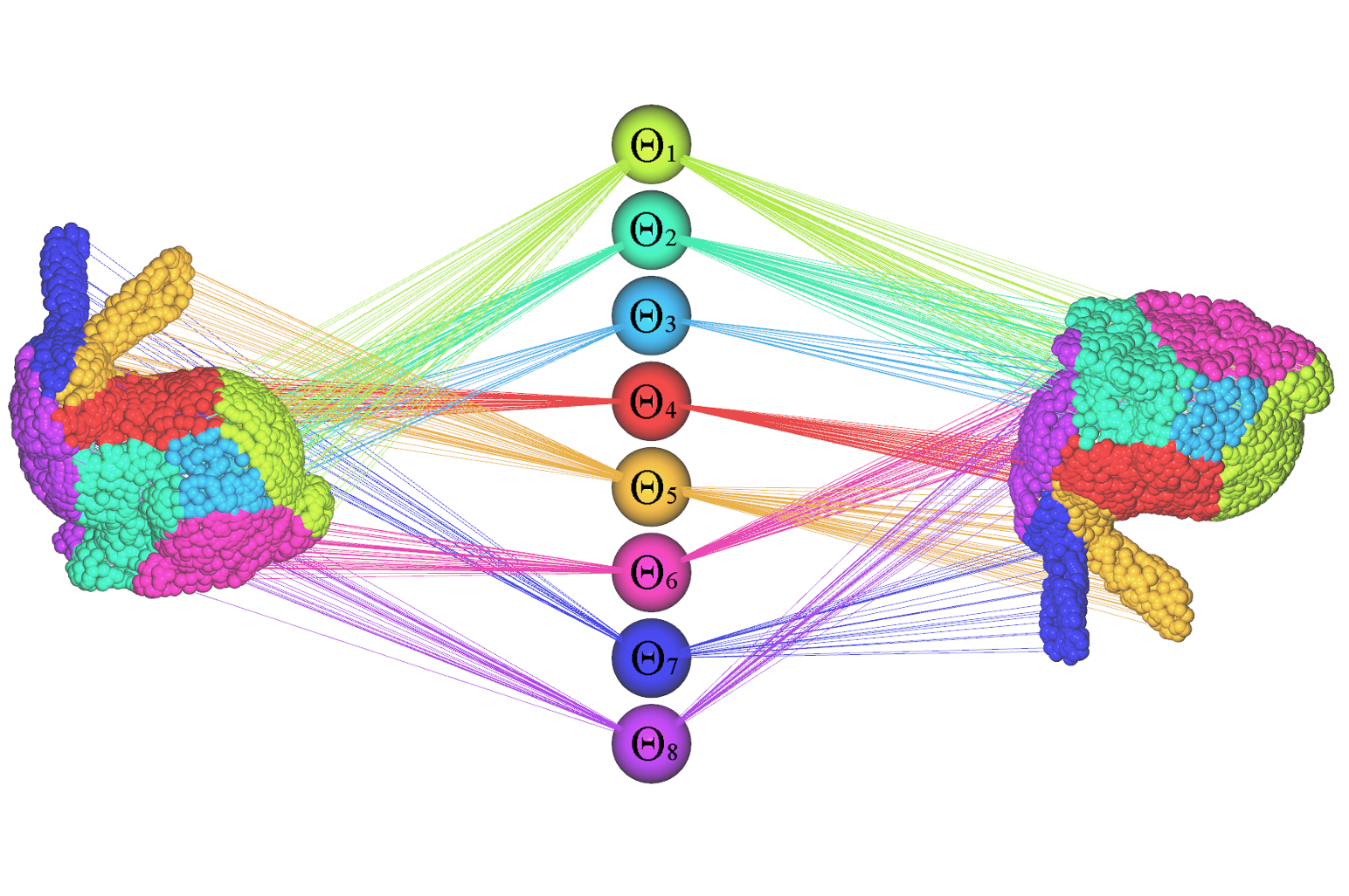
DeepGMR: Learning Latent Gaussian Mixture Models for Registration
Wentao Yuan, Ben Eckart, Kihwan Kim, Varun Jampani, Dieter Fox, Jan Kautz
European Conference on Computer Vision (ECCV), 2020 (Spotlight)
paper /
abstract /
code /
project page /
slides /
video /
bibtex
Point cloud registration is a fundamental problem in 3D computer vision, graphics and robotics. For the last few decades, existing registration algorithms have struggled in situations with large transformations, noise, and time constraints. In this paper, we introduce Deep Gaussian Mixture Registration (DeepGMR), the first learning-based registration method that explicitly leverages a probabilistic registration paradigm by formulating registration as the minimization of KL-divergence between two probability distributions modeled as mixtures of Gaussians. We design a neural network that extracts pose-invariant correspondences between raw point clouds and Gaussian Mixture Model (GMM) parameters and two differentiable compute blocks that recover the optimal transformation from matched GMM parameters. This construction allows the network learn an SE(3)-invariant feature space, producing a global registration method that is real-time, generalizable, and robust to noise. Across synthetic and real-world data, our proposed method shows favorable performance when compared with state-of-the-art geometry-based and learning-based registration methods.
@inproceedings{yuan2020deepgmr,
title={Deepgmr: Learning latent gaussian mixture models for registration},
author={Yuan, Wentao and Eckart, Benjamin and Kim, Kihwan and Jampani, Varun and Fox, Dieter and Kautz, Jan},
booktitle={European Conference on Computer Vision},
pages={733--750},
year={2020},
organization={Springer}
}
|
|
|
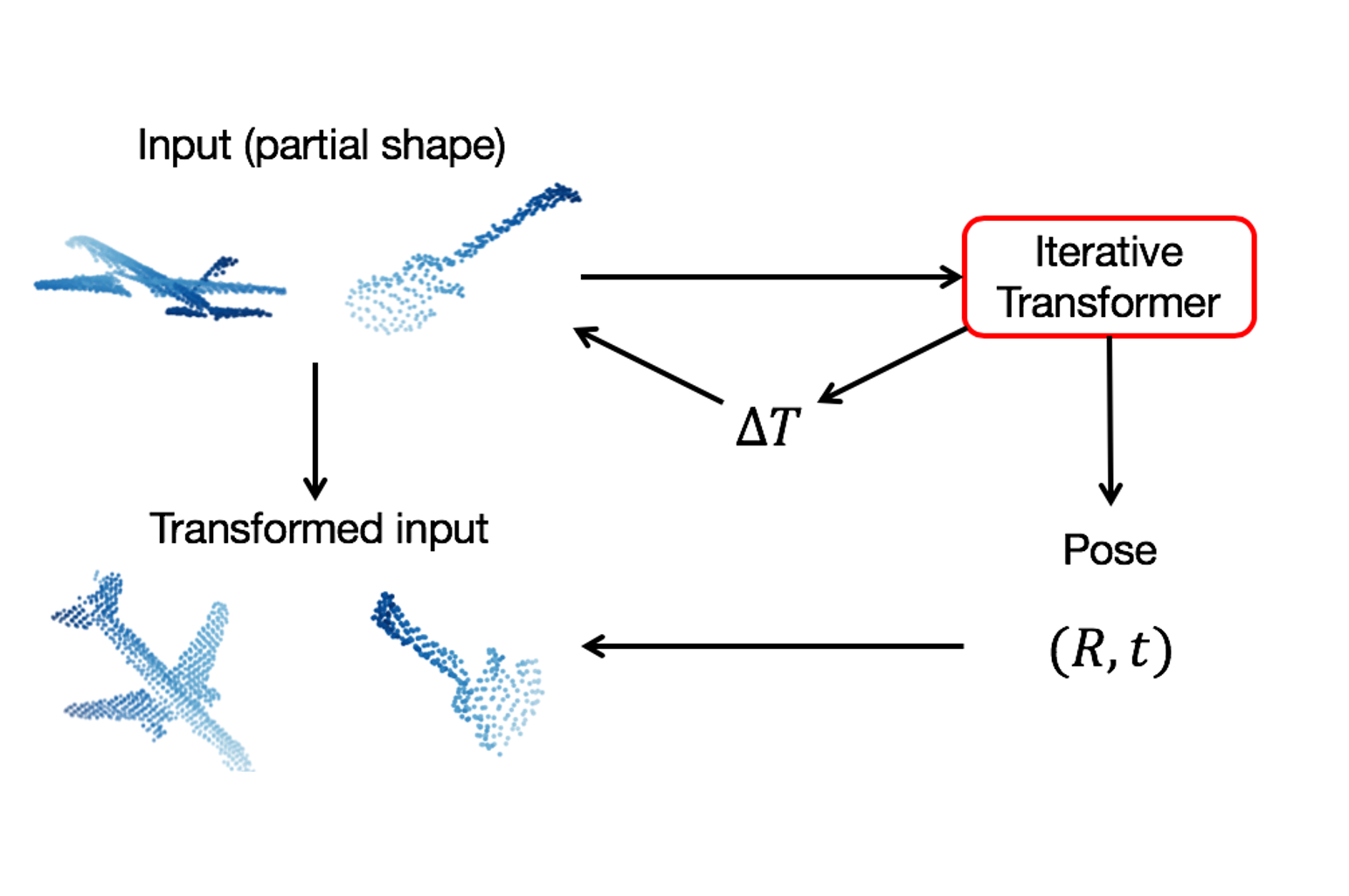
Iterative Transformer Network for 3D Point Cloud
Wentao Yuan, David Held, Christoph Mertz, Martial Hebert
CVPR Workshop on 3D Scene Understanding for Vision, Graphics, and Robotics, 2019
paper /
abstract /
code /
poster /
bibtex
3D point cloud is an efficient and flexible representation of 3D structures. Recently, neural networks operating on point clouds have shown superior performance on 3D understanding tasks such as shape classification and part segmentation. However, performance on such tasks is evaluated on complete shapes aligned in a canonical frame, while real world 3D data are partial and unaligned. A key challenge in learning from partial, unaligned point cloud data is to learn features that are invariant or equivariant with respect to geometric transformations. To address this challenge, we propose the Iterative Transformer Network (IT-Net), a network module that canonicalizes the pose of a partial object with a series of 3D rigid transformations predicted in an iterative fashion. We demonstrate the efficacy of IT-Net as an anytime pose estimator from partial point clouds without using complete object models. Further, we show that IT-Net achieves superior performance over alternative 3D transformer networks on various tasks, such as partial shape classification and object part segmentation.
@article{yuan2018iterative,
title={Iterative Transformer Network for 3D Point Cloud},
author={Yuan, Wentao and Held, David and Mertz, Christoph and Hebert, Martial},
journal={arXiv preprint arXiv:1811.11209},
year={2018}
}
|
|

|
PCN: Point Completion Network
Wentao Yuan, Tejas Khot, David Held, Christoph Mertz, Martial Hebert
International Conference on 3D Vision (3DV), 2018 (Oral)
[Best Paper Honorable Mention]
paper /
abstract /
code /
project page /
slides /
poster /
bibtex
Shape completion, the problem of estimating the complete geometry of objects from partial observations, lies at the core of many vision and robotics applications. In this work, we propose Point Completion Network (PCN), a novel learning-based approach for shape completion. Unlike existing shape completion methods, PCN directly operates on raw point clouds without any structural assumption (e.g. symmetry) or annotation (e.g. semantic class) about the underlying shape. It features a decoder design that enables the generation of fine-grained completions while maintaining a small number of parameters. Our experiments show that PCN produces dense, complete point clouds with realistic structures in the missing regions on inputs with various levels of incompleteness and noise, including cars from LiDAR scans in the KITTI dataset.
@inproceedings{yuan2018pcn,
title={PCN: Point Completion Network},
author={Yuan, Wentao and Khot, Tejas and Held, David and Mertz, Christoph and Hebert, Martial},
booktitle={2018 International Conference on 3D Vision (3DV)},
pages={728--737},
year={2018},
organization={IEEE}
}
|
|
More Publications
|

|
TerrainNet: Visual Modeling of Complex Terrain for High-speed, Off-road Navigation
Xiangyun Meng, Nathan Hatch, Alexander Lambert, Anqi Li, Nolan Wagener, Matthew Schmittle, JoonHo Lee, Wentao Yuan, Zoey Chen, Samuel Deng, Greg Okopal, Dieter Fox, Byron Boots, Amirreza Shaban
Robotics: Science and Systems (RSS), 2023
paper /
abstract /
project page /
bibtex
|
|
|
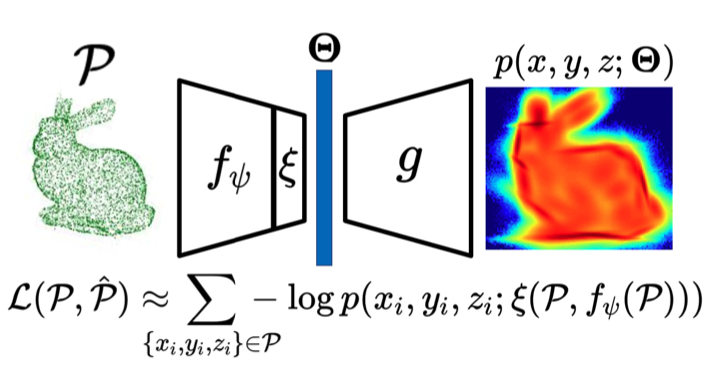
Self-Supervised Learning on 3D Point Clouds by Learning Discrete Generative Models
Benjamin Eckart, Wentao Yuan, Chao Liu, Jan Kautz
The Conference on Computer Vision and Pattern Recognition (CVPR), 2021
paper /
abstract /
bibtex
While recent pre-training tasks on 2D images have proven very successful for transfer learning, pre-training for 3D data remains challenging. In this work, we introduce a general method for 3D self-supervised representation learning that 1) remains agnostic to the underlying neural network architecture, and 2) specifically leverages the geometric nature of 3D point cloud data. The proposed task softly segments 3D points into a discrete number of geometric partitions. A self-supervised loss is formed under the interpretation that these soft partitions implicitly parameterize a latent Gaussian Mixture Model (GMM), and that this generative model establishes a data likelihood function. Our pretext task can therefore be viewed in terms of an encoder-decoder paradigm that squeezes learned representations through an implicitly defined parametric discrete generative model bottleneck. We show that any existing neural network architecture designed for supervised point cloud segmentation can be repurposed for the proposed unsupervised pretext task. By maximizing data likelihood with respect to the soft partitions formed by the unsupervised point-wise segmentation network, learned representations are encouraged to contain compositionally rich geometric information. In tests, we show that our method naturally induces semantic separation in feature space, resulting in state-of-the-art performance on downstream applications like model classification and semantic segmentation.
@inproceedings{eckart2021self,
title={Self-Supervised Learning on 3D Point Clouds by Learning Discrete Generative Models},
author={Eckart, Benjamin and Yuan, Wentao and Liu, Chao and Kautz, Jan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8248--8257},
year={2021}
}
|
|
|
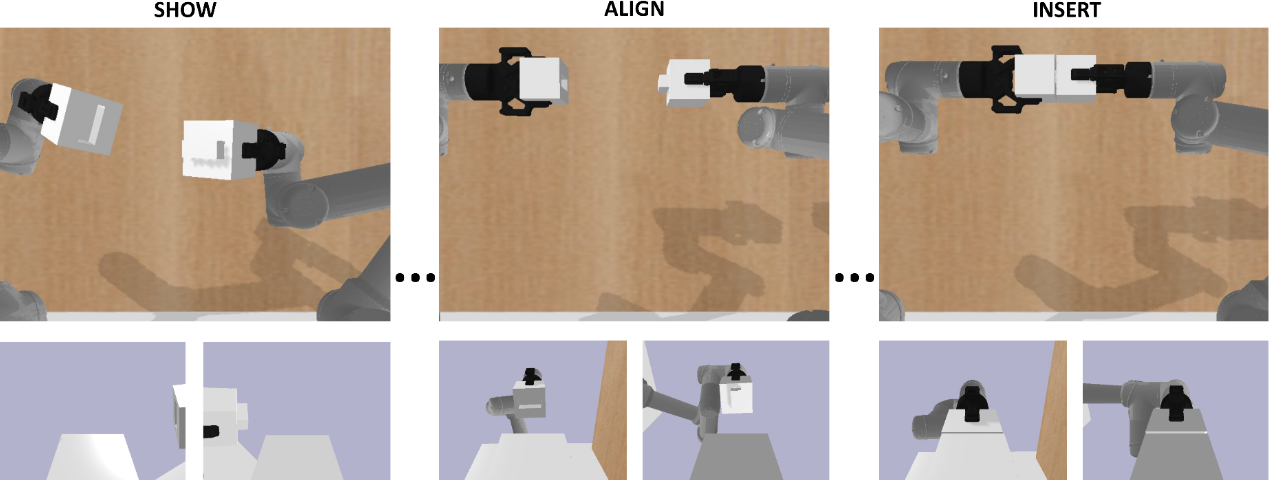
Evaluating Robustness of Visual Representations for Object Assembly Task Requiring Spatio-Geometrical Reasoning
Chahyon Ku, Carl Winge, Ryan Diaz, Wentao Yuan, Karthik Desingh
International Conference on Robotics and Automation (ICRA), 2024
paper /
abstract /
project page /
bibtex
This paper primarily focuses on evaluating and benchmarking the robustness of visual representations in the context of object assembly tasks. Specifically, it investigates the alignment and insertion of objects with geometrical extrusions and intrusions, commonly referred to as a peg-in-hole task. The accuracy required to detect and orient the peg and the hole geometry in SE(3) space for successful assembly poses significant challenges. Addressing this, we employ a general framework in visuomotor policy learning that utilizes visual pretraining models as vision encoders. Our study investigates the robustness of this framework when applied to a dual-arm manipulation setup, specifically to the grasp variations. Our quantitative analysis shows that existing pretrained models fail to capture the essential visual features necessary for this task. However, a visual encoder trained from scratch consistently outperforms the frozen pretrained models. Moreover, we discuss rotation representations and associated loss functions that substantially improve policy learning. We present a novel task scenario designed to evaluate the progress in visuomotor policy learning, with a specific focus on improving the robustness of intricate assembly tasks that require both geometrical and spatial reasoning.
@inproceedings{ku2024evaluating,
title={Evaluating Robustness of Visual Representations for Object Assembly Task Requiring Spatio-Geometrical Reasoning},
author={Ku, Chahyon and Winge, Carl and Diaz, Ryan and Yuan, Wentao and Desingh, Karthik},
booktitle={2024 IEEE International Conference on Robotics and Automation (ICRA)},
year={2024},
organization={IEEE}
}
|
|

|
Intelligent Shipwreck Search Using Autonomous Underwater Vehicles
Jeffrey Rutledge*, Wentao Yuan*, Jane Wu, Sam Freed, Amy Lewis, Zoe Wood, Timmy Gambin, Christopher Clark
International Conference on Robotics and Automation (ICRA), 2018
paper /
abstract /
bibtex
This paper presents an autonomous robot system that is designed to autonomously search for and geo-localize potential underwater archaeological sites. The system, based on Autonomous Underwater Vehicles, invokes a multi-step pipeline. First, the AUV constructs a high altitude scan over a large area to collect low-resolution side scan sonar data. Second, image processing software is employed to automatically detect and identify potential sites of interest. Third, a ranking algorithm assigns importance scores to each site. Fourth, an AUV path planner is used to plan a time-limited path that visits sites with a high importance at a low altitude to acquire high-resolution sonar data. Last, the AUV is deployed to follow this path. This system was implemented and evaluated during an archaeological survey located along the coast of Malta. These experiments demonstrated that the system is able to identify valuable archaeological sites accurately and efficiently in a large previously unsurveyed area. Also, the planned missions led to the discovery of a historical plane wreck whose location was previously unknown.
@inproceedings{rutledge2018intelligent,
title={Intelligent Shipwreck Search Using Autonomous Underwater Vehicles},
author={Rutledge, Jeffrey and Yuan, Wentao and Wu, Jane and Freed, Sam and Lewis, Amy and Wood, Zo{\"e} and Gambin, Timmy and Clark, Christopher},
booktitle={2018 IEEE International Conference on Robotics and Automation (ICRA)},
pages={1--8},
year={2018},
organization={IEEE}
}
|
|